As our research lead, JP produced an excel file of a tag glossary with his suggested tag names and available TEI tags/Orlando tags as references. Maria and I are working on designing the XML schema definition and the XML templates. As the PM, I listened to Gemma’s idea and thought it better to break our team into two: one research group and one web group. Even though this is not my original plan, due to time limitations and workload, this new plan is more practical and efficient. I designed a DTD (Document Type Definitions) for the XML encoding to describe the structure and specify the tag hierarchy and attributes. This method clearly guides us to place the same-named tags in different hierarchies or attributes. For example, I will give a short DTD below. This DTD is pending more edits, but I plan to use things like #PCDATA, #IMPLIED, symbols +, *, and ? to define the occurrence of attributes or child elements.

Following this DTD, we are going to format our individual director profiles. You will notice there is a in the example above. I designed this line to include a citation to include any hyperlink information. After talking to Prof. Cirasella, we think applying Hypothesis annotations is a good idea to direct readers to the source. Public annotations in the Hypothesis are in the public domain, and we could write the following encoding - example below. If the viewer does not have a Hypothesis account, the link will still direct them to the sidebar (my annotation that highlights the section I want them to read).

I have been working on my five directors during the break and tried to organize all XML files members sent me in a consistent style. This work directed to more work in making the DTDs and organizing the tag glossary. Our research group has made a tentative list of tags and their definitions, but I found some issues applying them to a long XML file of all directors. For example, how do we decide whether to use the tag “sponsor” or “investor” to describe the money and support one director received? These two words are similar but could work differently in some scenarios.
In our project, we recognized the value of drawing on various methodological resources, including individual expertise, interdisciplinary perspectives, and established guidelines. The key issue here is to collectively make valid XML files with individual tag brainstorming while keeping a consistency in defining the structure and DTDs. Our team referred to preexisting DTDs and standards to ensure consistency and compatibility while also allowing for the integration of customized tags to cater to our project's unique requirements.
The second question is: for the final result if we only want to show it as content on a web page (XML-XSLT-HTML), the structure is quite flexible. We could prepare individual XML files for each director, supported by the corresponding XSLT file. But the question will become complicated if we want to build database entries. We need to make sure the tag structure is clear, clean, and consistent to populate a database, allowing users to search, explore, or do computation studies. Interestingly, I have some initial findings: more than half of the women directors we examine are also either screenwriters or producers; many of them mentioned the tight funding issue; half of my current assigned directors started their careers with short films or commercials and transitioned to feature films.
I also discovered ways to do annotations on videos (Annotate.tv or https://docdrop.org/) and podcasts (Fathom, APP).
I tried the GitHub Copilot in VS code during the break to help me write the XML files. The result is good, but also terrifying. (https://code.visualstudio.com/docs/editor/artificial-intelligence) Copilot will suggest “Right Code but Wrong Content” to me. Accepting Copilot’s suggestion won’t make my XML tree crash but will help spread the wrong information. See the picture below, Copilot suggests a code to me, but the Hypothesis link in grey does not exist, and I have never made such annotations.
Dear Journal,
First and foremost,
I hope everyone had a fantastic break! Our team managed to get some 'breathing space' as everyone had the chance to either travel or see their beloved ones - or both! Nevertheless, we all kept working with alacrity on the project.
The research team provided additional directors' bios and further contents to upload to our website, and compiled more XML files which are in the process of being reviewed for the search engine functionality. Personally, I have connected with almost everyone during the break to chat about how to manage online contents and what to display in our final webpage.
The list of tags has grown exponentially, which was somehow expected considering how difficult it is to map one's life (especially someone we do not personally know) based on what is available online. Work is in progress to consolidate the list we currently have and related definitions.
It is noticeable how the project has shifted from a relatively niche subset of filmmakers to a much broader pool of artists - I believe the more we explore the more we find unrecognized talents (particularly women) across a vast range of regions. In this sense, we are attempting to find an easy way to present our efforts during the final presentation as we are in agreement on how difficult it might be for someone outside our project to get a clear grasp of the purpose of our 'datification' mission.
This week while I am producing more XML files for the five directors, I am trying to design a mechanism to showcase how flexible and transformable XML files could be. My first trial is about XML-XSLT-HTML, which means I use XSLT (Extensible Stylesheet Language Transformations) to transfer my XML code into HTML for web content. And here is the screenshot of my result.
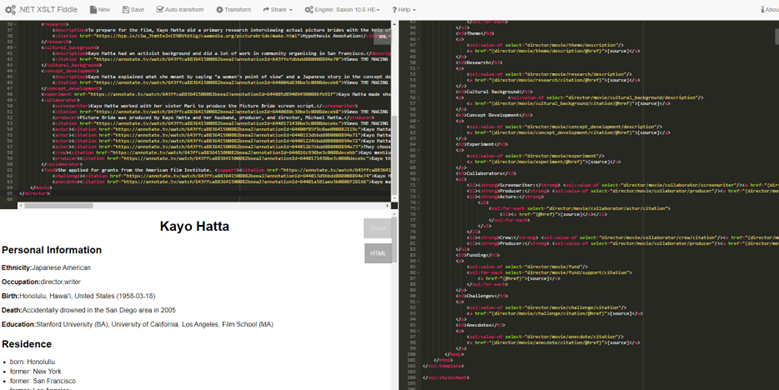
As you can see in my XML file (upper left), I have adjusted the structure in XSLT five times to get the current result (button left). So then, I will ask members to revisit their structures and give me the files. I will guide everybody through the DTD and XSLT tomorrow; ideally, we will get three pilot samples that we could show on our website. A total of 15 XML files will be saved in our shared folder. We decided to do 3 pilot example HTML pages, and instead of only showing the final result, we will tell the behind-the-scenes story with screenshots or screen recordings of our codes. The time probably wouldn’t allow us to do all 15 in this XML-XSLT-HTML format, but if anyone follows our workflow, they could get an HTML code by spending some time and effort. Designing our DTDs and XSLT is difficult because we encode our files individually. It is just so hard to do collective encoding this semester due to time limits and course structure. We couldn’t build a mechanism like the Orlando project in such a short time, so we tried our best to give pilots and show our workflow. You might notice that we use different tags, and even for one director, for different films, some tags appear, and some do not. (Because for some films, we just couldn’t find that much information). So, in this case, we need to give a conditional code in XSLT as xsl: if to make sure there is no empty content in our display. This if logic also works in our DTDs in which a question mark appears after the element like this “”, indicating that the element is optional (it can be present once or not at all). While we give an example of XML-XSLT-HTML, there are also possible options for JSON, CSV, SQL database, or mobile applications. Our search functionality is a JavaScript supported transformation of our original XML files.